MySQL学习笔记(Day015-Day016:索引/B+树/Explain)
一. 索引
1. 索引的定义
索引是对记录按照一个或者多个字段进行排序的一种方式。对表中的某个字段建立索引会创建另一种数据结构,其中保存着字段的值,每个值又指向与它相关的记录。这种索引的数据结构是经过排序的,因而可以对其执行二分查找。且性能较高
2. 二分查找
摘自《MySQL技术内幕:InnoDB存储引擎(第2版)》5.2.1 小节
二分查找法(binary search)也称为折半查找法,用来查找一组有序的记录数组中的某一记录,其基本思想是:将记录按有序化(递增或递减)排列,在查找过程中采用跳跃式方式查找,即先以有序数列的中点位置作为比较对象,如果要找的元素值小于该中点元素,则将待查序列缩小为左半部分,否则为右半部分。通过一次比较,将查找区间缩小一半。(O(logN)的时间复杂度)
1 | # 给出一个例子,注意该例子已经是升序排序的,且查找 数字 48 |
步骤一:设
low为下标最小值0,high为下标最大值9;步骤二:通过
low和high得到mid,mid=(low + high) / 2,初始时mid为下标4*(也可以=5,看具体算法实现)*;**
步骤三**:mid=4对应的数据值是31,31 < 48(我们要找的数字);步骤四:通过二分查找的思路,将
low设置为31对应的下标4,high保持不变为9,此时mid为6;**
步骤五**:mid=6对应的数据值是42,42 < 48(我们要找的数字);步骤六:通过二分查找的思路,将
low设置为42对应的下标6,high保持不变为9,此时mid为7;**
步骤七**:mid=7对应的数据值是48,48 == 48(我们要找的数字),查找结束;通过3次
二分查找就找到了我们所要的数字,而顺序查找需8次。
二. 二叉树(Binary Tree)
1. 二叉树的定义
每个节点至多只有二棵子树;
二叉树的子树有左右之分,次序不能颠倒;
一棵深度为k,且有 个节点,称为满二叉树(Full Tree);
一棵深度为k,且root到k-1层的节点树都达到最大,第k层的所有节点都
连续集中在最左边,此时为完全二叉树(Complete Tree)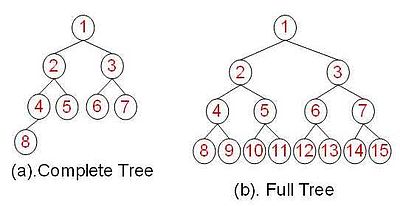
2. 平衡二叉树(AVL-树)
左子树和右子树都是平衡二叉树;
左子树和右子树的高度差绝对值不超过1;
- 平衡二叉树
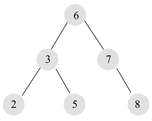
- 非平衡二叉树
- 平衡二叉树
平衡二叉树的遍历 以上面平衡二叉树的图例为样本,进行遍历:
前序:6, 3, 2, 5, 7, 8(ROOT节点在开头,中-左-右 顺序)中序:2, 3, 5,6, 7, 8(中序遍历即为升序,左-中-右 顺序)后序:2, 5, 3, 8, 7,6(ROOT节点在结尾,左-右-中顺序)
1:可以通过
前序和中序或者是后序和中序来推导出一个棵树 2:前序或者后序用来得到ROOT节点,中序可以区分左右子树平衡二叉树的旋转
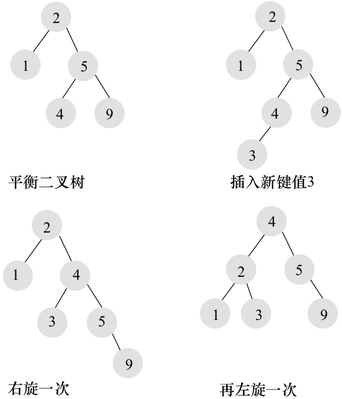
1 | >需要通过旋转(左旋,右旋)来维护平衡二叉树的平衡,在添加和删除的时候需要有额外的开销。 |
三. B树/B+树
注意:B树和B+树开头的
B不是Binary,而是Balance
1. B树的定义
阶为M (节点上关键字(Keys)的个数) 的B树的定义:
- 每个节点最多有M个孩子;
- 除了root节点外,每个非叶子(non-leaf)节点至少含有(M/2)个孩子;
- 如果root节点不为空,则root节点至少要有两个孩子节点;
- 一个非叶子(non-leaf)节点如果含有K个孩子,则包含k-1个keys;
- 所有叶子节点都在同一层;
- B树中的非叶子(non-leaf)节点也包含了数据部分;
2. B+树的定义
在B树的基础上,B+树做了如下改进
- 数据只存储在叶子节点上,非叶子节点只保存索引信息;
- 非叶子节点(索引节点)存储的只是一个Flag,不保存实际数据记录;
- 索引节点指示该节点的左子树比这个Flag小,而右子树大于等于这个Flag
- 叶子节点本身按照数据的升序排序进行链接(串联起来);
- 叶子节点中的数据在
物理存储上是无序的,仅仅是在逻辑上有序(通过指针串在一起);
- 叶子节点中的数据在
3. B+树的作用
- 在块设备上,通过B+树可以有效的存储数据;
- 所有记录都存储在叶子节点上,非叶子(non-leaf)存储索引(keys)信息;
- B+树含有非常高的扇出(fanout),通常超过100,在查找一个记录时,可以有效的减少IO操作;
3. B+树的操作
B+树的插入 B+树的插入必须保证插入后叶子节点中的记录依然排序。
- 插入操作步骤(引用自姜老师的书《MySQL技术内幕:InnoDB存储引擎(第2版)》 第5.3.1小节)
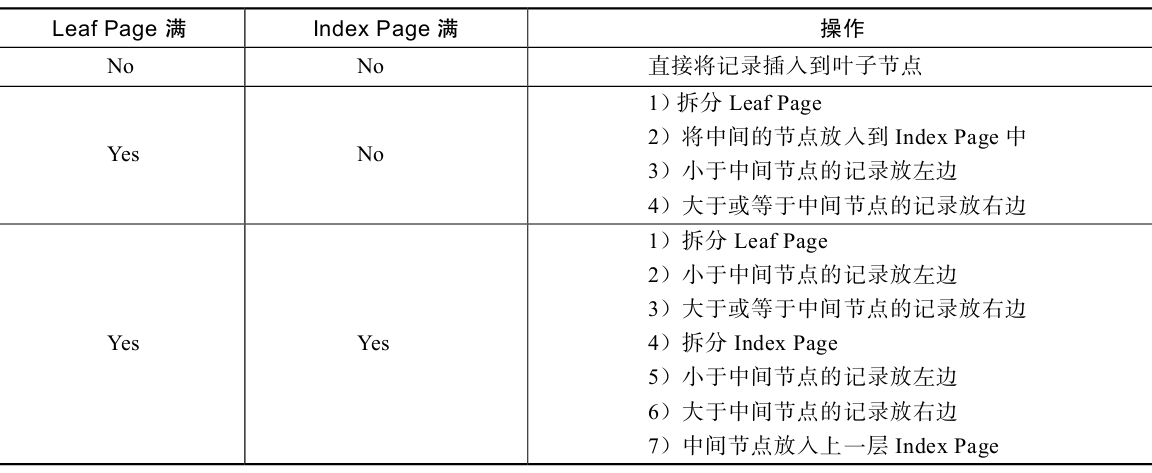
B+树总是会保持平衡。但是为了保持平衡对于新插入的键值可能需要做大量的拆分页(split)操作;部分情况下可以通过B+树的旋转来替代拆分页操作,进而达到平衡效果。
- 插入操作步骤(引用自姜老师的书《MySQL技术内幕:InnoDB存储引擎(第2版)》 第5.3.1小节)
B+树的删除 B+树使用填充因子(fill factor)来控制树的删除变化,50%是填充因子可设的最小值。B+树的删除操作同样必须保证删除后叶子节点中的记录依然排序。与插入不同的是,删除根据填充因子的变化来衡量。
- 删除操作步骤(引用自姜老师的书《MySQL技术内幕:InnoDB存储引擎(第2版)》 第5.3.2小节)
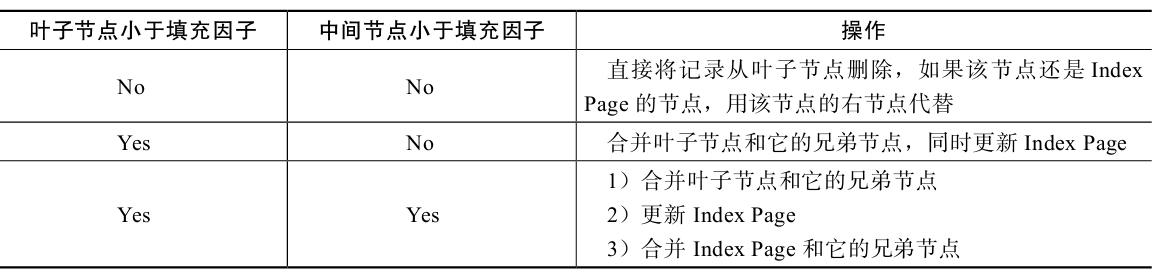
- 删除操作步骤(引用自姜老师的书《MySQL技术内幕:InnoDB存储引擎(第2版)》 第5.3.2小节)
3. B+树的扇出(fan out)
- B+树图例
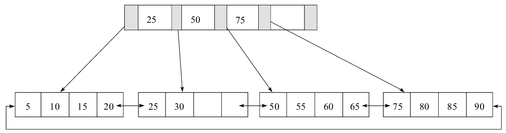
- 该 B+ 树高度为 2
- 每叶子页(LeafPage)4条记录
扇出数为5- 叶子节点(LeafPage)由小到大(有序)串联在一起
扇出是每个索引节点(Non-LeafPage)指向每个叶子节点(LeafPage)的指针扇出数= 索引节点(Non-LeafPage)可存储的最大关键字个数 + 1 图例中的索引节点(Non-LeafPage)最大可以存放4个关键字,但实际使用了3个;
4. B+树存储数据举例
假设B+树中页的大小是16K,每行记录是200Byte大小,求出树的高度为1,2,3,4时,分别可以存储多少条记录。
查看数据表中每行记录的平均大小
1
mysql> show table status like "%employees%"\G
1
*************************** 1. row ***************************
1
Name: employees
1
Engine: InnoDB
1
Version: 10
1
Row_format: Dynamic
1
Rows: 298124
1
Avg_row_length: 51 -- 平均长度为51个字节
1
Data_length: 15245312
1
Max_data_length: 0
1
Index_length: 0
1
Data_free: 0
1
Auto_increment: NULL
1
Create_time: 2015-12-02 21:32:02
1
Update_time: NULL
1
Check_time: NULL
1
Collation: utf8mb4_general_ci
1
Checksum: NULL
1
Create_options:
1
Comment:
1
1 row in set (0.00 sec)
高度为1
- 16K/200B 约等于 80 个记录(数据结构元信息如指针等忽略不计)
高度为2 非叶子节点中存放的仅仅是一个索引信息,包含了
Key和Point指针;Point指针在MySQL中固定为6Byte。而Key我们这里假设为8Byte,则单个索引信息即为14个字节,KeySize = 14Byte- 高度为2,即有一个索引节点(索引页),和N个叶子节点
- 一个索引节点可以存放 16K / KeySize = 16K / 14B = 1142个索引信息,即有(1142 + 1)个扇出,以及有(1142 + 1)个叶子节点(数据页) (可以简化为1000)
- 数据记录数 = (16K / KeySize + 1)x (16K / 200B) 约等于 80W 个记录
高度为3 高度为3的B+树,即ROOT节点有1000个扇出,每个扇出又有1000个扇出指向叶子节点。每个节点是80个记录,所以一共有 8000W个记录
高度为4 同高度3一样,高度为4时的记录书为(8000 x 1000)W
上述的8000W等数据只是一个理论值。线上实际使用单个页的记录数字要乘以70%,即第二层需要70% x 70% ,依次类推。
因此在数据库中,B+树的高度一般都在2~4层,这也就是说查找某一键值的行记录时最多只需要2到4次IO,2~4次的IO意味着查询时间只需0.02~0.04秒(假设IOPS=100,当前SSD可以达到50000IOPS)。
从5.7开始,页的预留大小可以设置了,以减少split操作的概率(空间换时间)
四. MySQL索引
1. MySQL 创建索引
1 | -- |
2. MySQL 查看索引
1 | -- |
3. Cardinality(基数)
Cardinality表示该索引列上有多少不同的记录,这个是一个预估的值,是采样得到的(由InnoDB触发,采样20个页,进行预估),该值越大越好,即当Cardinality / RowNumber 越接近1越好。表示该列是高选择性的。
- 高选择性:身份证 、手机号码、姓名、订单号等
- 低选择性:性别、年龄等
即该列是否适合创建索引,就看该字段是否具有高选择性
1 | mysql> show create table lineitem\G |
对应当前例子 第一个索引(Seq_in_index = 1)的
Cardinality的值表示当前列(l_orderkey)的不重复的值, 第二个索引(Seq_in_index = 2)的Cardinality的值表示前两列(l_orderkey)和(l_linenumber)不重复的值
1 | -- |
innodb_on_state = off在MySQL5.5之前,执行show create table操作会触发采样,而5.5之后将该参数off后,需要主动执行analyze table才会去采样。采样不会锁表或者锁记录。
4. 复合索引
1 | mysql> show create table lineitem\G |
五. information_schema(一)
1 | mysql> use information_schema; |
六. EXPLAIN (一)
explain是解释SQL语句的执行计划,即显示该SQL语句怎么执行的
- 使用
explain的时候,也可以使用desc
- 使用
5.6 版本支持DML语句进行explain解释
5.6 版本开始支持
JSON格式的输出注意:EXPLAIN查看的是执行计划,做SQL解析,不会去真的执行;且到5.7以后子查询也不会去执行。
参数extended
1 | mysql> explain extended select * from test_index_2 where b >1 and b < 3\G |
- 参数FORMAT
- 使用
FORMART=JSON不仅仅是为了格式化输出效果,还有其他有用的显示信息。 - 且当5.6版本后,使用
MySQL Workbench,可以使用visual Explain方式显示详细的图示信息。
- 使用
1 | mysql> explain format=json select * from test_index_2 where b >1 and b < 3\G |