Java堆内存分配
ava堆内存:概述、堆的结构、对象的内存布局
Java堆内存的概述:
Java堆用来存放应用系统创建的对象和数组,所有线程共享Java堆
Java堆内存在逻辑上是连续的,在物理上是不用连续的
实现的时候,堆的大小可以是固定的也可以是扩展的,在不能扩展的时候进行扩展会抛出运行时异常(RunOutOfMerroy)
❤:Java堆是在运行期动态分配内存大小,自动进行垃圾回收
Java垃圾回收(GC)主要就是回收堆内存,对分代GC来说,堆也是分代的
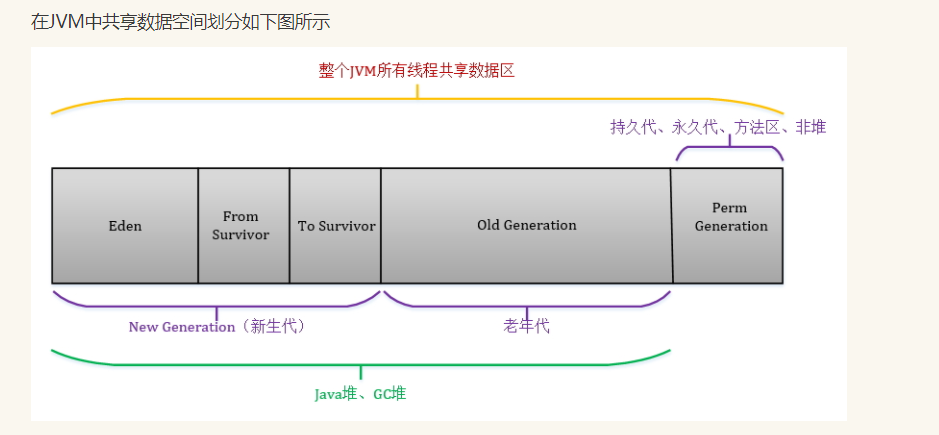
1.JVM中共享数据空间可以分成三个大区,新生代(Young Generation)、老年代(Old Generation)、永久代(Permanent Generation),其中JVM堆分为新生代和老年代
2.新生代可以划分为三个区,Eden区(存放新生对象),两个幸存区(From Survivor和To Survivor)(存放每次垃圾回收后存活的对象)
3.永久代管理class文件、静态对象、属性等(JVM uses a separate region of memory, called the Permanent Generation (orPermGen for short), to hold internal representations of java classes. PermGen is also used to store more information )
4.JVM垃圾回收机制采用“分代收集”:新生代采用复制算法,老年代采用标记清理算法。
作为操作系统进程,Java 运行时面临着与其他进程完全相同的内存限制:操作系统架构提供的可寻址地址空间和用户空间。
操 作系统架构提供的可寻址地址空间,由处理器的位数决定,32 位提供了 2^32 的可寻址范围,也就是 4,294,967,296 位,或者说 4GB。而 64 位处理器的可寻址范围明显增大:2^64,也就是 18,446,744,073,709,551,616,或者说 16 exabyte(百亿亿字节)。
地址空间被划分为用户空间和内核空间。内核是主要的操作系统程序和C运行时,包含用于连接计算机硬件、调度程序以及提供联网和虚拟内存等服务的逻辑和基于C的进程(JVM)。除去内核空间就是用户空间,用户空间才是 Java 进程实际运行时使用的内存。
默认情况下,32 位 Windows 拥有 2GB 用户空间和 2GB 内核空间。在一些 Windows 版本上,通过向启动配置添加 /3GB 开关并使用 /LARGEADDRESSAWARE 开关重新链接应用程序,可以将这种平衡调整为 3GB 用户空间和 1GB 内核空间。在 32 位 Linux 上,默认设置为 3GB 用户空间和 1GB 内核空间。一些 Linux 分发版提供了一个hugemem内核,支持 4GB 用户空间。为了实现这种配置,将进行系统调用时使用的地址空间分配给内核。通过这种方式增加用户空间会减慢系统调用,因为每次进行系统调用时,操作系统必须在地址空间之间复制数据并重置进程地址-空间映射。
下图为一个32 位 Java 进程的内存布局:

可寻址的地址空间总共有 4GB,OS 和 C 运行时大约占用了其中的 1GB,Java 堆占用了将近 2GB,本机堆占用了其他部分。请注意,JVM 本身也要占用内存,就像 OS 内核和 C 运行时一样。
注意:
上文提到的可寻址空间即指最大地址空间。
对于2GB的用户空间,理论上Java堆内存最大为1.75G,但一旦Java线程的堆达到1.75G,那么就会出现本地堆的Out-Of-Memory错误,所以实际上Java堆的最大可使用内存为1.5G。
在JVM运行时,可以通过配置以下参数改变整个JVM堆的配置比例
Java heap的大小(新生代+老年代)
-Xms堆的最小值
-Xmx堆空间的最大值
2.新生代堆空间大小调整
-XX:NewSize新生代的最小值
-XX:MaxNewSize新生代的最大值
-XX:NewRatio设置新生代与老年代在堆空间的大小
-XX:SurvivorRatio新生代中Eden所占区域的大小3.永久代大小调整
-XX:MaxPermSize4.其他
-XX:MaxTenuringThreshold,设置将新生代对象转到老年代时需要经过多少次垃圾回收,但是仍然没有被回收在上面的配置中,老年代所占空间的大小是由-XX:SurvivorRatio这个参数进行配置的,看完了上面的JVM堆空间分配图,可能会奇怪,为啥新生代空间要划分为三个区Eden及两个Survivor区?有何用意?为什么要这么分?要理解这个问题,就得理解一下JVM的垃圾收集机制(复制算法也叫copy算法),步骤如下:
复制(Copying)算法
将内存平均分成A、B两块,算法过程:
新生对象被分配到A块中未使用的内存当中。当A块的内存用完了, 把A块的存活对象对象复制到B块。
清理A块所有对象。
新生对象被分配的B块中未使用的内存当中。当B块的内存用完了, 把B块的存活对象对象复制到A块。
清理B块所有对象。
goto 1。
优点:简单高效。缺点:内存代价高,有效内存为占用内存的一半。
图解说明如下所示:(图中后观是一个循环过程)
对复制算法进一步优化:使用Eden/S0/S1三个分区
平均分成A/B块太浪费内存,采用Eden/S0/S1三个区更合理,空间比例为Eden:S0:S1==8:1:1,有效内存(即可分配新生对象的内存)是总内存的9/10。
算法过程:
Eden+S0可分配新生对象;
对Eden+S0进行垃圾收集,存活对象复制到S1。清理Eden+S0。一次新生代GC结束。
Eden+S1可分配新生对象;
对Eden+S1进行垃圾收集,存活对象复制到S0。清理Eden+S1。二次新生代GC结束。
goto 1。
默认Eden:S0:S1=8:1:1,因此,新生代中可以使用的内存空间大小占用新生代的9/10,那么有人就会问,为什么不直接分成两个区,一个区占9/10,另一个区占1/10,这样做的原因大概有以下几种
S0与S1的区间明显较小,有效新生代空间为Eden+S0/S1,因此有效空间就大,增加了内存使用率
有利于对象代的计算,当一个对象在S0/S1中达到设置的XX:MaxTenuringThreshold值后,会将其分到老年代中,设想一下,如果没有S0/S1,直接分成两个区,该如何计算对象经过了多少次GC还没被释放,你可能会说,在对象里加一个计数器记录经过的GC次数,或者存在一张映射表记录对象和GC次数的关系,是的,可以,但是这样的话,会扫描整个新生代中的对象, 有了S0/S1我们就可以只扫描S0/S1区了
~

Java堆的结构:
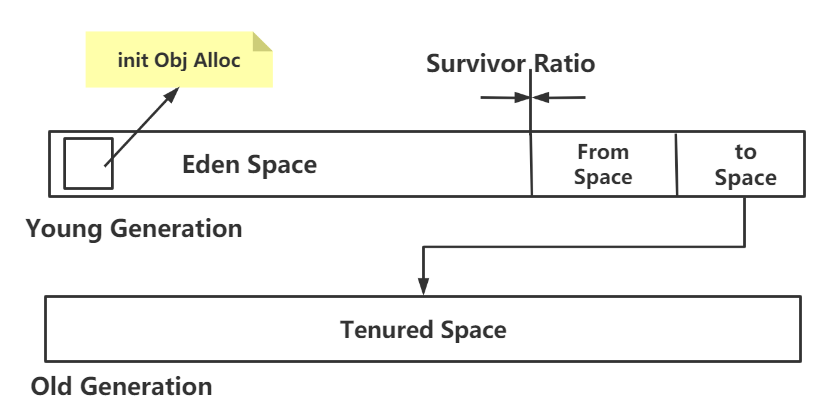
新生代用来放新分配的对象;新生代中经过垃圾回收,没有回收掉的对象,被复制到老年代
老年代存储对象比新生代存储的对象的年龄大得多
老年代存储一些大对象
整个堆大小 = 新生代 + 老年代
新生代 = Eden + 存活区
❤:从前的持久代,用来存放Class、Method等元信息的区域,从JDK8开始去掉了,取而代之的是元空间(MetaSpace),元空间并不在虚拟机里面,而是直接使用本地内存
对象在内存布局
对象在内存中存储的布局(这里以HotSpot虚拟机为例来说明),分为:对象头、实例数据和对齐填充
对象头,包含两个部分:
1)Mark Word:存储对象自身的运行数据,如:HashCode、GC分代年龄、锁状态标志等
2)类型指针:对象指向它的类元数据的指针
实例数据
真正存放对象实例数据的地方
对其填充:
这部分不一定存在,也没有什么特别含义,仅仅是占位符。
因为HotSpot要求对象起始地址都是8字节的整数倍,如果不是,就对齐
对象的访问定位
对象的访问定位:在JVM规范中只规定了reference类型是一个指向对象的应用,但没有规定这个应用具体如何去定位、访问堆中对象的具体位置
❤:因此对象的访问方式取决于JVM的实现:目前主流的有:
- 使用句柄
- 使用指针
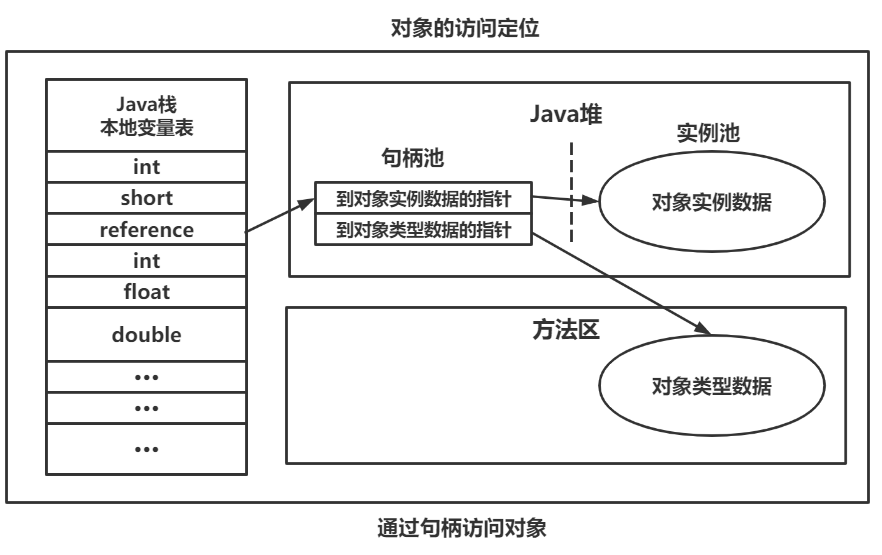
使用句柄:Java堆中会划分出一块内存来做为句柄池,reference中储存句柄的地址,句柄中储存对象的实例数据和类元数据的地址,如下图所示:
使用指针:Java堆中会存放类元数据的地址,reference存储的就直接是对象的地址,如下图所示:
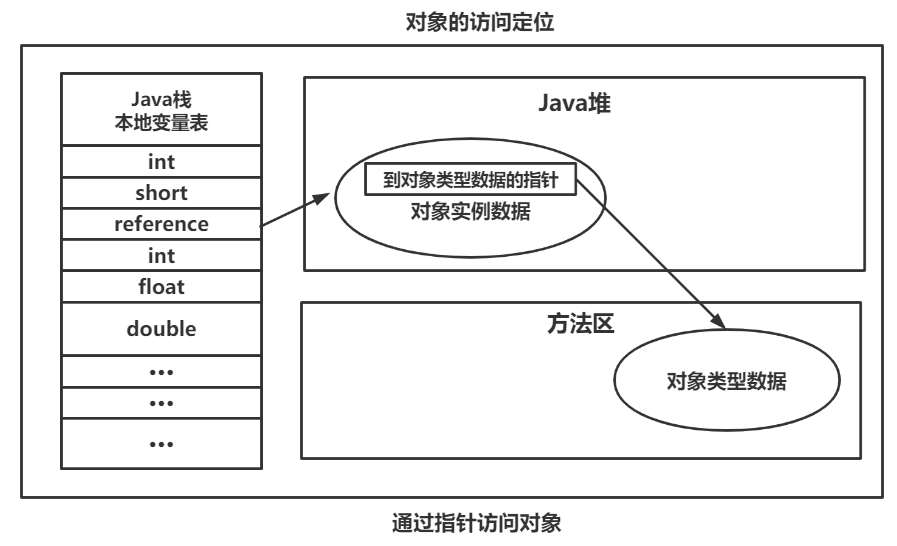
(HotSpot采用指针的方式进行访问)
Java堆内存:重点是理解Java堆内存的特点、掌握堆的结构,了解对象的内存布局